In the evolution of PostgreSQL, the executor has always been one of its core components, directly impacting query performance. As more and more data analytics workloads are brought into the database, improving executor performance has become a continuous focus of the PostgreSQL community. Last year, Amit Langote, in his talk “Hacking Postgres Executor For Performance” at PGConf India 2025, explored in depth the ideas and practices for optimizing the PostgreSQL executor. In this talk, he introduced some limitations of the standard PostgreSQL executor and discussed how improving the execution model can enhance database performance under analytical workloads. Extensibility has always been one of PostgreSQL’s most important advantages. In the past, we often discussed capabilities such as data type extensions, index access methods, FDW, plugins, and hooks. Recently, I presented a topic on YMatrix mxvector at PGConf — “How to implement high performance pluggable vectorized executor”. In this talk, the key message is that PostgreSQL’s extensibility is not only about extending functionality, but also about enabling the evolution of execution models. mxvector is a practical implementation in this direction: without rewriting the PostgreSQL executor, it builds an analytical execution path better suited for OLAP/HTAP scenarios.
The PostgreSQL executor adopts a classic tuple-at-a-time model (row-by-row processing).It can be understood as a model where “parent nodes continuously request the next tuple from child nodes.”Each node behaves like an iterator: the parent node calls next() on the child node and pulls data one tuple at a time.This model performs very well in OLTP scenarios, efficiently handling workloads such as point queries and transaction processing.During execution, the database processes each record sequentially, performing computations, filtering, projection, and other operations one by one.However, when workloads shift to OLAP or HTAP scenarios, row-by-row processing becomes inefficient.Especially in queries involving large volumes of data, processing each tuple introduces significant overhead.
When executing analytical queries, the PostgreSQL standard executor goes through many steps, such as data extraction, function calls, and type conversions. Although each step seems inexpensive for a single tuple, their cumulative cost becomes substantial as data volume increases, significantly degrading query performance. Consider a simple predicate evaluation such as c1 < 10.
The standard executor performs the following steps:
The scan operator loads a tuple from storage, where data is stored in a serialized format such as a heap tuple;
It extracts the value of c1 from the heap tuple, converts it into a datum, populates it into the function call context, and invokes a function pointer to the C function int4lt() to perform the comparison;
The boolean comparison result is then converted into a generic datum and returned;
After returning to the scan operator, the result is converted back from datum to bool to determine whether the filter condition is satisfied.
The pseudocode is as follows:

As we can see, even for a simple comparison that can be completed by a single CPU instruction, a large number of additional operations are performed before and after the instruction. Compared to the actual comparison operation, these surrounding operations may dominate the cost, even by several to tens of times. When this process is repeated millions or tens of millions of times, it significantly impacts the throughput of analytical queries. Innovation of the Vectorized Executor Why can a vectorized executor significantly improve performance? Let’s consider an intuitive example: suppose we need to sort out all apples weighing more than 200 grams.
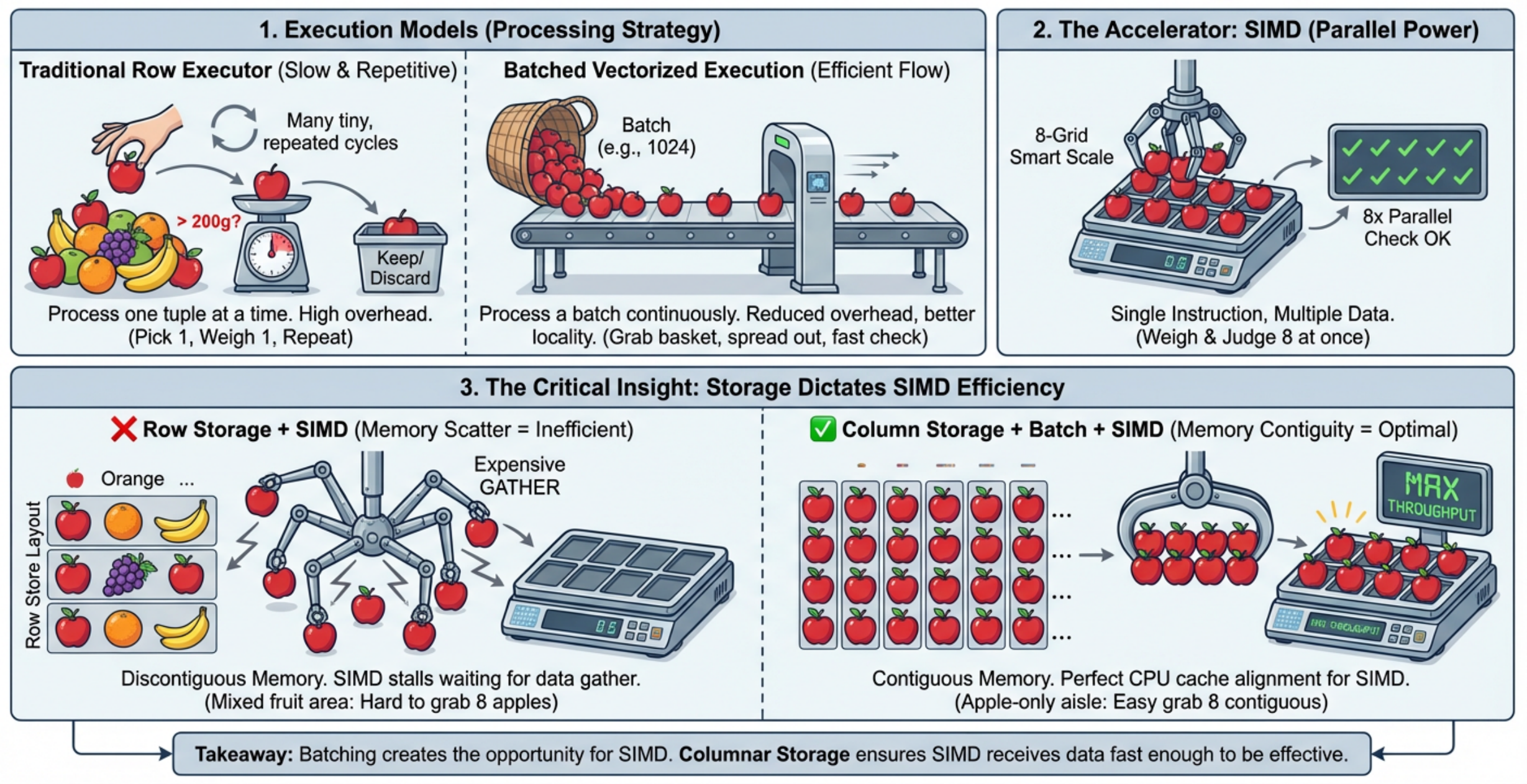
Under the traditional execution model, the process is like this:
pick up one apple, weigh it, check if it exceeds 200 grams, put it down, and repeat for the next apple until all apples are processed. This approach works, but the problem is obvious: for each apple, the full sequence of “pick up → weigh → check → put down” is repeated. If there are only a few apples, this is fine. But if there are millions, the repeated overhead becomes enormous. So naturally, we consider the first optimization: Can we process a batch instead of one at a time? Suppose we now have a basket that can hold 100 apples. The process changes: instead of repeatedly initiating operations for each apple, we process a batch continuously. The benefit is clear: the fixed overhead (such as pick up/put down) is amortized across the entire batch. In databases, this corresponds to batch processing. Its core value is not simply processing more data at once, but changing the execution granularity from “one record per operation” to “a batch per operation,” thereby reducing repeated function calls, state transitions, and data conversion overhead. Next question: since apples are already processed in batches, can we weigh multiple apples simultaneously? This leads to the second optimization: SIMD. Imagine a scale that can weigh 8 apples at once. Instead of weighing each apple individually, one operation produces 8 results. This is the essence of SIMD — one instruction processes multiple data elements. In databases, if we have a batch of homogeneous data (e.g., int32 values), the CPU can process multiple elements at once using SIMD instructions instead of scalar computation. However, there is a prerequisite: batch processing and SIMD require well-organized data. This leads to the third key point: storage layout. If fruits are stored randomly (apples, oranges, bananas mixed together), even with a SIMD-capable scale, we must first separate apples. This resembles row-oriented storage: a row contains multiple columns, and extracting a specific column requires decoding the entire row. In contrast, if all apples are stored together, we can directly process them in batches. This corresponds to columnar storage, where data of the same column is stored contiguously.
Columnar storage provides several advantages:
Queries read only required columns, reducing unnecessary I/O;
Homogeneous data improves compression efficiency;
Contiguous data benefits CPU cache locality;
Data naturally resembles arrays, making it suitable for batch processing and SIMD.
Thus, columnar storage, batch processing, and SIMD are not independent concepts, but a progressive chain:
Columnar storage improves data locality
Batch processing regularizes execution
SIMD enables parallel computation at the CPU level
Batch processing creates opportunities for SIMD, and columnar storage allows SIMD to be effective. Summary of Vectorized Execution The core idea of a vectorized executor is to transform data processing from “row-by-row” to “batch-based,” making data access and computation more continuous, structured, and CPU-friendly. It relies on three key capabilities:
Columnar storage: store data by column to reduce I/O and improve compression and cache locality;
Batch processing: process multiple records at once to reduce repeated overhead;
SIMD acceleration: use CPU vector instructions to process multiple data elements simultaneously.
These improvements reduce per-tuple overhead and better align execution with modern CPU architectures, significantly improving analytical query performance.
After understanding the value of vectorization, the next question is how to implement it.
There are three main approaches:
Modify the standard executor directly This approach is unified but risky. The PostgreSQL executor is complex and mature; intrusive changes may affect OLTP behavior.
Introduce a new executor inside PostgreSQL core This increases architectural complexity and maintenance cost, as planner, executor, expression, and storage layers must support dual logic.
Build a pluggable vectorized executor (mxvector approach) This approach is low-intrusion, on-demand, and coexists with the traditional executor, preserving PostgreSQL’s OLTP strengths.
In short, we do not want to sacrifice PostgreSQL’s OLTP advantages for analytical performance.
Pluggable design: mxvector is loaded as a plugin and coexists with the standard executor;
Leverages PostgreSQL extensibility: built using hooks, CustomScan, AM adapters, etc., without modifying core code;
Compatibility fallback: falls back to the scalar executor when vectorization is unavailable.
The implementation of mxvector primarily relies on the following key techniques.
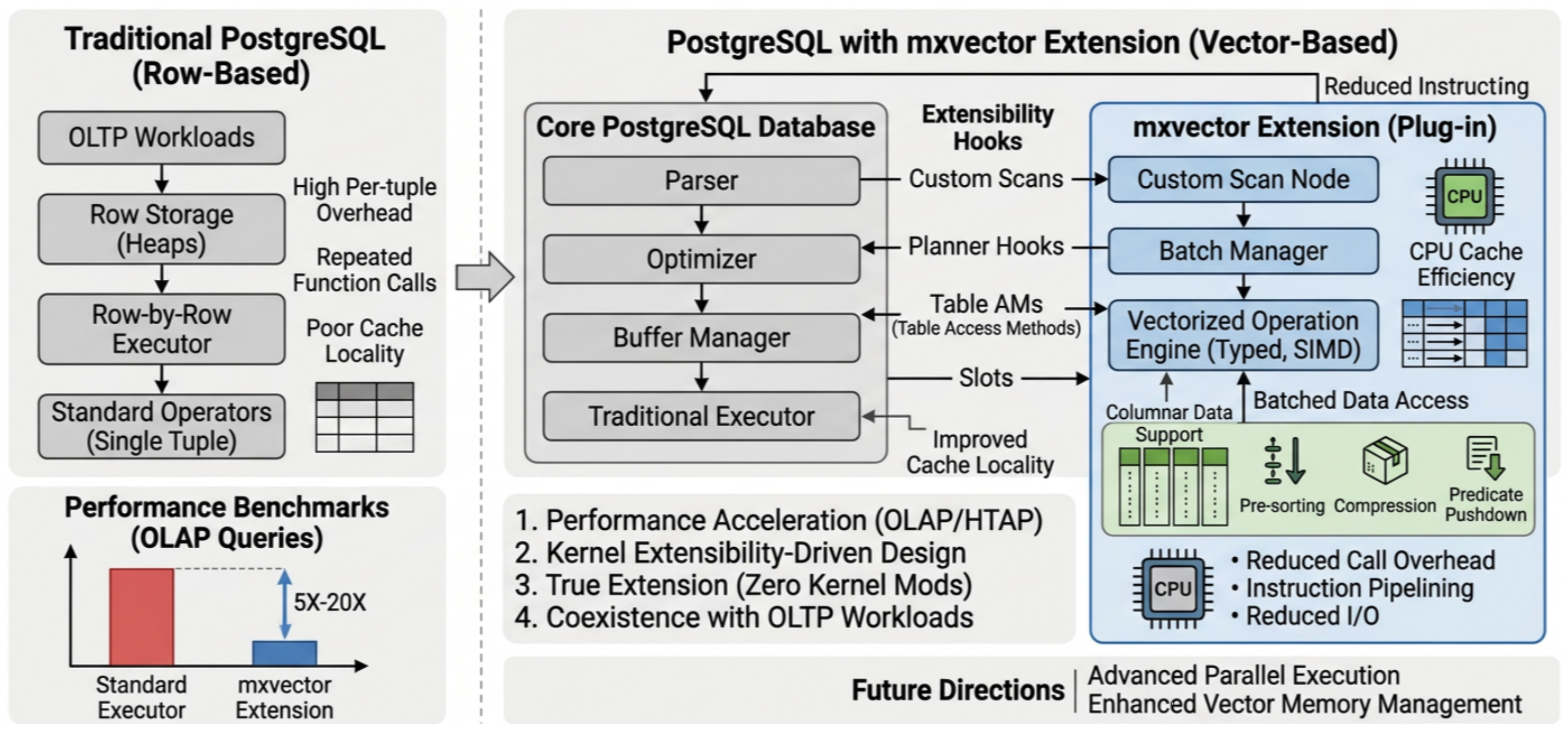
A PostgreSQL execution plan is composed of various executor nodes, such as SeqScan, Sort, and Agg. mxvector requires its own vectorized counterparts, such as VScan, VSort, and VHashJoin. The question is: how can these nodes be legitimately introduced into the PostgreSQL plan tree? The answer is CustomScan. CustomScan provides a mechanism for defining custom execution nodes, allowing extensions to attach their own nodes into PostgreSQL’s plan tree and executor framework.
VPlanner is responsible for plan-level transformation. For example, PostgreSQL may originally generate a plan like:
Limit
-> Sort
-> Seq Scanmxvector overlays a corresponding vectorized node on top of each scalar node, resulting in a structure like:
VLimit
-> Limit
-> VSort
-> Sort
-> VScan
-> Seq ScanHere, the scalar nodes are referred to as shadow nodes. These shadow nodes are not actually executed, but they preserve the semantic information and execution details of the original plan. For example:
VLimit retrieves OFFSET / LIMIT information from the Limit shadow node
VSort retrieves sort keys from the Sort shadow node
VScan retrieves scan-related metadata from the SeqScan shadow node
This design is critical, as it avoids the need for mxvector to reimplement the entire plan semantic interpretation logic.
A VNode is the vectorized counterpart of a scalar node. It is built on top of the CustomScan API and can be embedded directly into the PostgreSQL plan tree. Examples include:
VScan for vectorized scanning
VSort for vectorized sorting
VHashJoin for vectorized hash joins
VLimit for vectorized limit operations
The direct child of a VNode is a shadow node, but the shadow node itself is not executed. Instead, the VNode extracts semantic information from the shadow node, while fetching columnar batch data from its own vectorized child. This design achieves two key objectives:
Preserving the original PostgreSQL plan semantics
Executing through mxvector’s batch-oriented, columnar, and vectorized execution path
In the PostgreSQL executor, data is typically passed between nodes using TupleTableSlot. Traditional slots are designed for passing a single tuple. However, mxvector needs to handle:
columnar data
batch data
zero-copy data
To address this, mxvector introduces VSlot. VSlot inherits from TupleTableSlot, but supports batch-oriented columnar data transfer, and can convert back to row format when needed. This allows it to serve both the vectorized executor and remain compatible with the traditional executor. Therefore, VSlot can be characterized not only as a compatibility bridge, but also as a high-performance internal data channel within mxvector.
A large portion of SQL logic is expressed through expressions, including:
filter predicates
projection expressions
arithmetic expressions
type casts
function calls
aggregate arguments
mxvector needs to convert these scalar expressions into vectorized expressions. If a native vectorized implementation exists, the high-performance version is used. If not, a fallback expression is applied, which simulates batch execution using scalar logic. This enables mxvector to:
prioritize acceleration on high-impact execution paths
ensure correctness for complex or unsupported expressions
avoid query failures due to incomplete coverage
The AM adapter acts as a bridge between existing table/index access methods and the vectorized executor. Traditional table/index access methods are typically row-oriented, whereas mxvector expects batched columnar data. Therefore, an adapter is required to transform the underlying data access interface into a format suitable for vectorized execution. Meanwhile, YMatrix’s columnar storage engine provides a data foundation better suited for vectorized execution, featuring:
built on the Table Access Method API
type-based encoding
block-level micro- metadata filtering
ordered scan
aggregated scan
automatic sorting
This means that the storage layer is not merely responsible for persisting data, but is actively preparing data for efficient vectorized computation at the upper layers.
The traditional PostgreSQL executor excels in OLTP scenarios but faces performance bottlenecks in OLAP and HTAP workloads. Vectorized execution introduces a new high-performance execution path through batch processing, columnar storage, and SIMD. With mxvector, we preserve PostgreSQL’s OLTP strengths while introducing a pluggable high-performance analytical execution path. By leveraging PostgreSQL’s extensibility, this approach enhances analytical performance without impacting core functionality.
Looking ahead, further improvements in memory management and parallel execution will continue to enhance PostgreSQL’s capabilities, especially for large-scale analytics and real-time data processing, driving PostgreSQL toward a more versatile and efficient future.
PXF: Cross-Source Queries in Seconds with YMatrix
From Greenplum to YMatrix: Migrating Core Business Data for a Leading Power-Battery Manufacturer
Cost Reduction of RMB 30 Million! YMatrix Helps Customer Save 100 Servers
How a Leading ERP Vendor Entered the AI Fast Lane — A YMatrix Field Story
How MARS3 Works: Hybrid Row/Column Storage for High-Frequency Writes and Fast Analytics
How YMatrix Domino Replaces Lambda, Kappa, Flink, and Spark with One Engine🚀