Blog/
Blog/
For over a decade, the data engineering world has pursued the ideal of unified batch and stream processing. From Lambda to Kappa architectures, the prevailing approach has been stitching together various technologies and components to simulate this integration. But the reality? Engineers end up juggling multiple tools, while ops teams maintain two or more distinct systems in parallel.
Think about a food delivery platform during peak hours: it must process real-time orders (stream processing) while analyzing historical subsidy data (batch processing). Traditional architectures ask the same system to deliver food and manage warehouse logistics simultaneously — leading to chaos and inefficiency.
YMatrix Domino changed the game. By integrating stream and batch processing directly at the kernel level, Domino functions like an intelligent traffic hub: real-time data takes express lanes, batch data travels on freight routes, and all are governed by a unified signaling system. This innovation redefines the paradigm of data processing.
Domino breaks down the traditional mental barrier between tables and streams. It treats streaming data and static tables as different representations of the same data entity. In this model, a stream is simply a continuous series of table updates, while batch is a snapshot of that stream at a given point in time.
Imagine a tea cup with water continuously pouring in:

Domino’s innovation is the ability to preserve the trajectory of the stream, enabling snapshots on demand. This magic comes from the Stream Table, a native abstraction that combines table semantics with stream properties and supports incremental, real-time computation.
Example:
CREATE STREAM dwd_order_detail(id, ts, prod_id, prod_name, prod_detail)
AS (
SELECT
ods_order.id,
ods_order.ts,
ods_order.prod_id,
dim_prod.prod_name,
dim_prod.prod_detail
FROM STREAMING ALL ods_order
INNER JOIN dim_prod
ON dim_prod.id = ods_order.prod_id
) PRIMARY KEY (id);This stream table acts like a regular table that supports queries, but also reflects real-time updates whenever the source data changes (INSERT/UPDATE/DELETE).
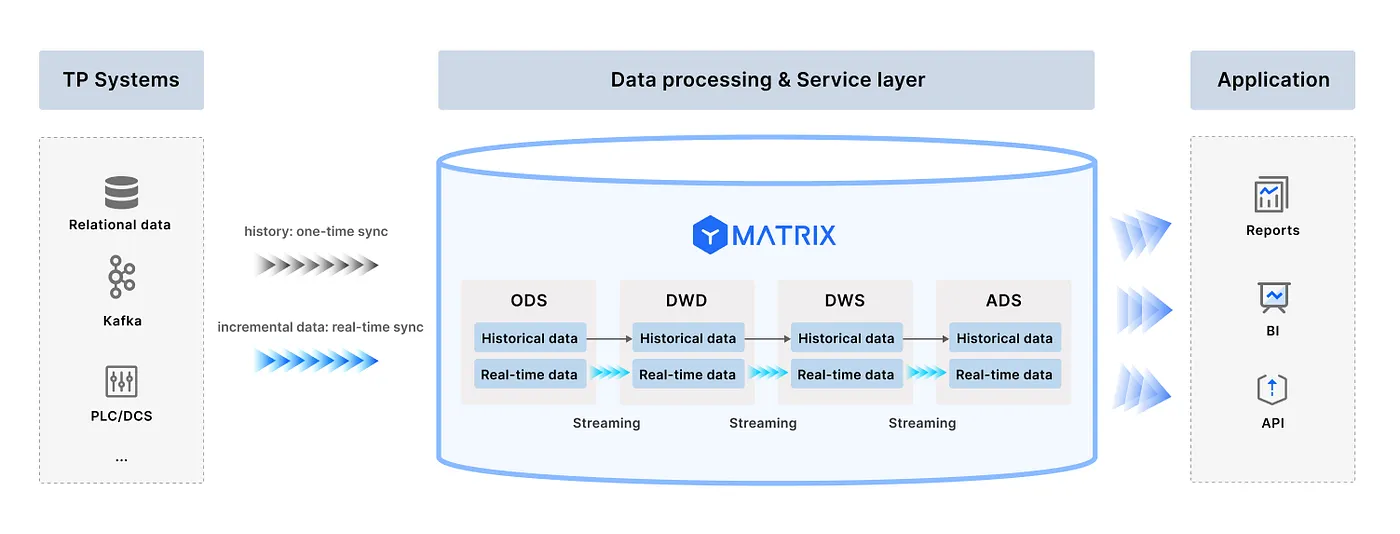
Domino standardizes ingestion for both batch and stream using SQL. Developers no longer need to learn different interfaces or tools for ingesting real-time versus historical data. This not only reduces redundancy caused by format and API inconsistencies, but also lowers the entry barrier for developers.
With tables as the core abstraction, modifying or deleting data is straightforward — even in streaming scenarios.
Both batch and stream tasks run on the same pipeline-based execution engine, following the Volcano model — a time-tested standard in database systems. When users define a stream table, Domino auto-generates execution plans. These are triggered when source data changes, keeping stream table results up to date.
This unified execution model allows developers to work entirely in SQL, with no need to manage dual pipelines or complex event logic.
Domino stores both batch (table) and stream (stream table) data using the same engine, ensuring durability and ACID consistency. With this model, there’s no need to worry about memory limits or small window sizes common in traditional streaming systems.
In Domino, there are no fixed windows or watermarks — just continuous data stored reliably, ready to be queried or computed as needed. This reduces overhead and boosts performance by eliminating the friction between compute and storage layers.
Domino extends standard SQL to cover stream processing capabilities. Instead of learning Java, Scala, or Python, developers can express complex real-time and historical transformations using only SQL.
For instance:
SELECT * FROM order_stream WHERE subsidy_amount > 50;This single query supports both real-time fraud detection and offline analytics.
Domino empowers developers to do more with less — writing once in SQL and deploying to both batch and stream contexts.
Domino integrates with a wide range of upstream and downstream systems including FineDataLink, DSG, DataPipeline, Seatunnel, BluePipe, UFIDA IUAP, EMQ, Talend, and more.
Whether data comes from IoT, enterprise systems, log collectors, or external APIs, Domino acts as a universal connector — standardizing and unifying ingestion.
Traditional streaming engines rely heavily on windows and watermarks to handle unbounded data. These mechanisms often complicate logic and debugging.
Domino’s approach eliminates these constructs by leveraging unified storage and execution, along with built-in transactional guarantees. Developers can forget about window boundaries and late-arriving data — Domino handles consistency and correctness automatically.
Conclusion: A True Kernel-Level Breakthrough
Domino represents a generational leap in data processing architecture. With unified ingestion, storage, computation, and a SQL-centric approach, it breaks down the silos that have long divided batch and stream systems.
Now, developers fluent in SQL can master real-time analytics without learning new languages or managing complex toolchains. For organizations, this means lower complexity, reduced costs, and greater agility.
Domino is more than a product — it’s the beginning of the “unified everything” era.
Key Advantages of YMatrix Domino Compared to Flink/Spark:
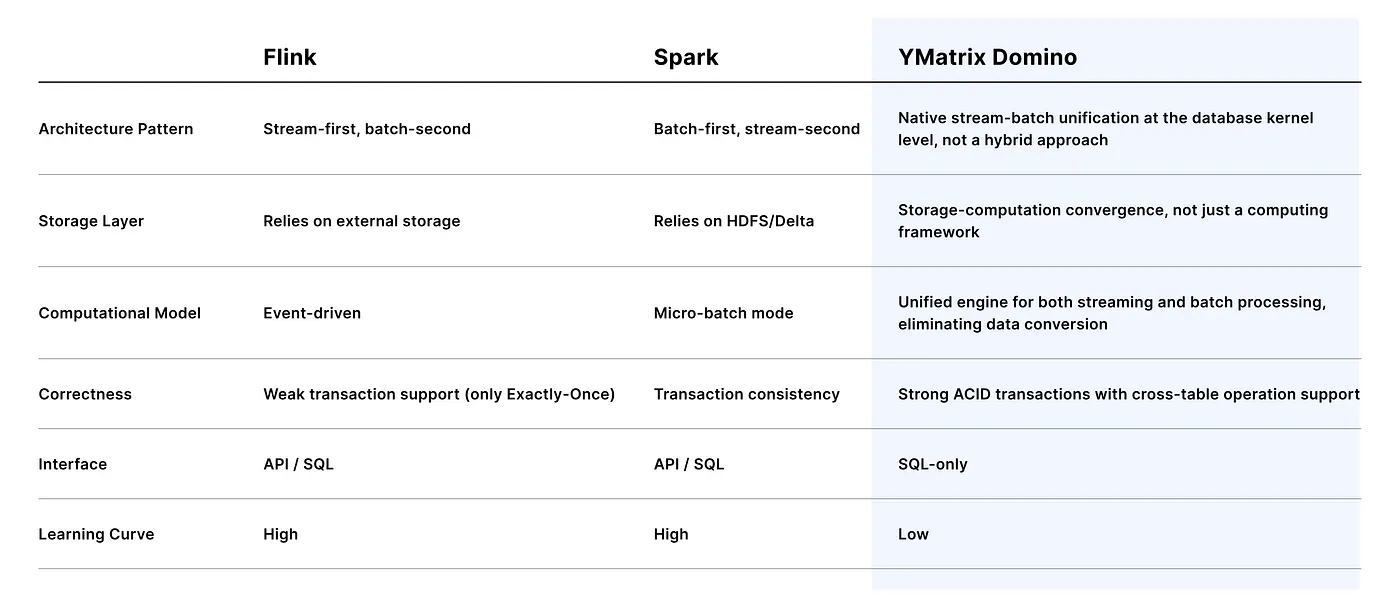
YMatrix Domino: The only database-native architecture that truly unifies batch and stream.
Originally published at https://ymatrix.ai