YMatrix
Quick Start
Simulate Time Series Scenarios
Standard Cluster Deployment
Data Modeling
Connecting to The database
Data Writing
Data Migration
Data Query
Scene Application Examples
Federal Query
Maintenance and Monitoring
Global Maintenance
Partition Maintenance
Backup and Restore
Cluster Expansion
Monitoring
Performance Tuning
Troubleshooting
Reference Guide
Tool Guide
Data Type
Storage Engine
Execution Engine
Configuration Parameters
Index
Extension
SQL Reference
FAQ
This document introduces the data writing characteristics in time series scenarios and YMatrix's data writing architecture in time series scenarios.
Storage is one of the core functions of a database. After completing data modeling and database connection, data must be written to the table.
Time series scenario writes mainly have the following characteristics:
A typical characteristic of data writing in time series scenarios is large data scale, which is reflected in three aspects in actual scenarios:
In summary, under the influence of the ever-growing number of entities and high collection frequency, the amount of data generated in time series scenarios is enormous, posing a great challenge to the throughput performance of databases.
YMatrix has developed the MatrixGate high-speed write tool, which achieves a maximum write speed of hundreds of millions of data points per second through a parallel data ingestion approach using data nodes (Segments).
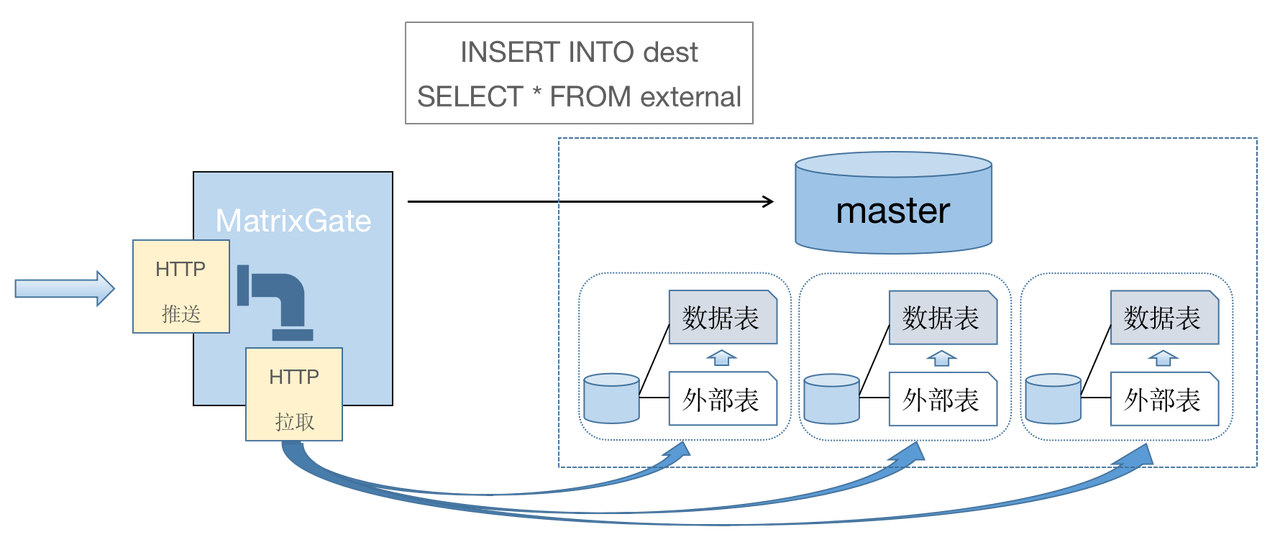
Notes!
For details on how it works, see Data Input Tool.
In real-world scenarios, data writing faces not only issues such as large data volumes and diverse data sources, but also complex abnormal situations, such as:
In certain scenarios, the metrics collected by a device at a given time are not sent back all at once but are instead transmitted in batches. The data from multiple transmissions needs to be merged into a single record rather than stored as multiple separate records.
For such scenarios, YMatrix supports handling this through the UPSERT feature. For a detailed explanation of this scenario and the usage of the UPSERT feature, see Batch Data Merging Scenario (UPSERT).
Delayed reporting refers to situations where data cannot be reported on time due to device failure or issues at a specific node in the data collection chain. Once the data collection chain returns to normal, the data is reported. For example, after a vehicle enters an area with no signal and drives for several days, it will resume reporting when it enters an area with signal coverage. Such delays can often be measured in days, and in some cases even weeks.
Out-of-order reporting occurs when a device malfunctions or a node in the data collection chain fails, causing reporting to be delayed. After the issue is resolved, the system may first report the latest data and then gradually fill in the missing data. In such cases, out-of-order reporting occurs, meaning the reported data may be older than previously reported data.
Since these two scenarios typically do not require special data merging processing by the database, further details are omitted here.
Different frequencies refer to different indicators of a device being collected at different frequencies, for example, some are collected once every 1 second, while others are collected once every 2 seconds. As shown in the figure below:
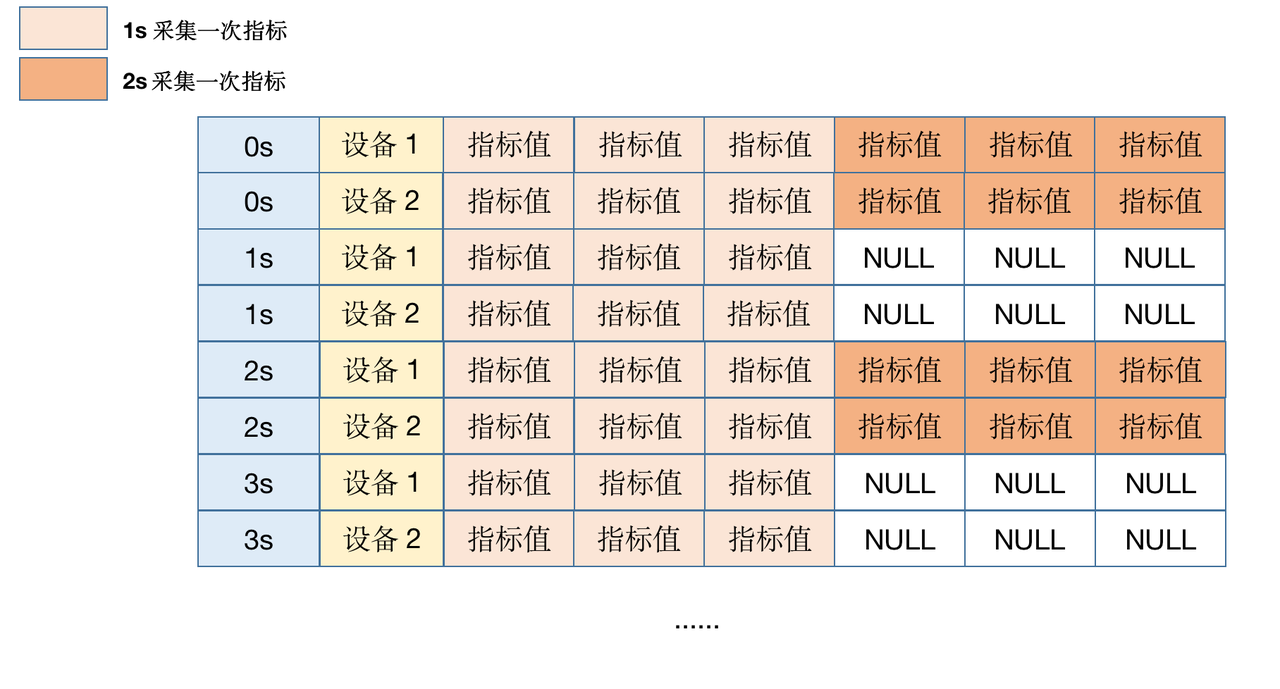
Asynchronous reporting can result in a large number of NULL values in low-frequency collected metric values during data storage, and NULL values also occupy a certain amount of storage space: for HEAP tables, the storage overhead is the number of columns divided by 8 bytes; for MARS2 tables, the storage overhead is the number of rows in the RowGroup divided by 8 bytes. Therefore, solutions should be considered comprehensively based on the NULL situation.
YMatrix can connect multiple sources and different forms of data to its own system. The following figure shows common data sources and storage formats.
Notes!
Click on the corresponding icon to jump to the corresponding document.