In traditional database architectures, as data volume grows, query complexity increases, and real-time write workloads intensify, the number of servers typically scales linearly or even super-linearly. In such scenarios, capacity expansion is often the most straightforward response: more data means adding storage; slower queries mean adding CPU; higher concurrency means adding nodes; increased real-time analytics pressure means deploying an additional stream processing system.
But today, this approach is becoming increasingly expensive. The rapid expansion of AI infrastructure continues to push up the price baseline of the server. Public data shows that in Q1 2026, conventional DRAM contract prices rose by approximately 90%–95% quarter-over-quarter. In Q2, DRAM is expected to further increase by 58%–63%, while NAND Flash contract prices are projected to rise by 70%–75%. IDC data also shows that global server market revenue grew by 80.4% year-over-year in 2025, with Q4 alone up 52.4% year-over-year.
Taking a typical database node as an example, a dual-socket CPU configuration, hundreds of GB of memory, multiple enterprise-grade SSD/NVMe drives, high-speed networking, RAID cards, and a three-year vendor warranty can easily bring the cost of a single server to RMB 300,000–400,000 or more. If we further include rack space, power, networking, backup systems, maintenance, and operational labor, the total cost of ownership (TCO) over a three-year period becomes significantly higher.
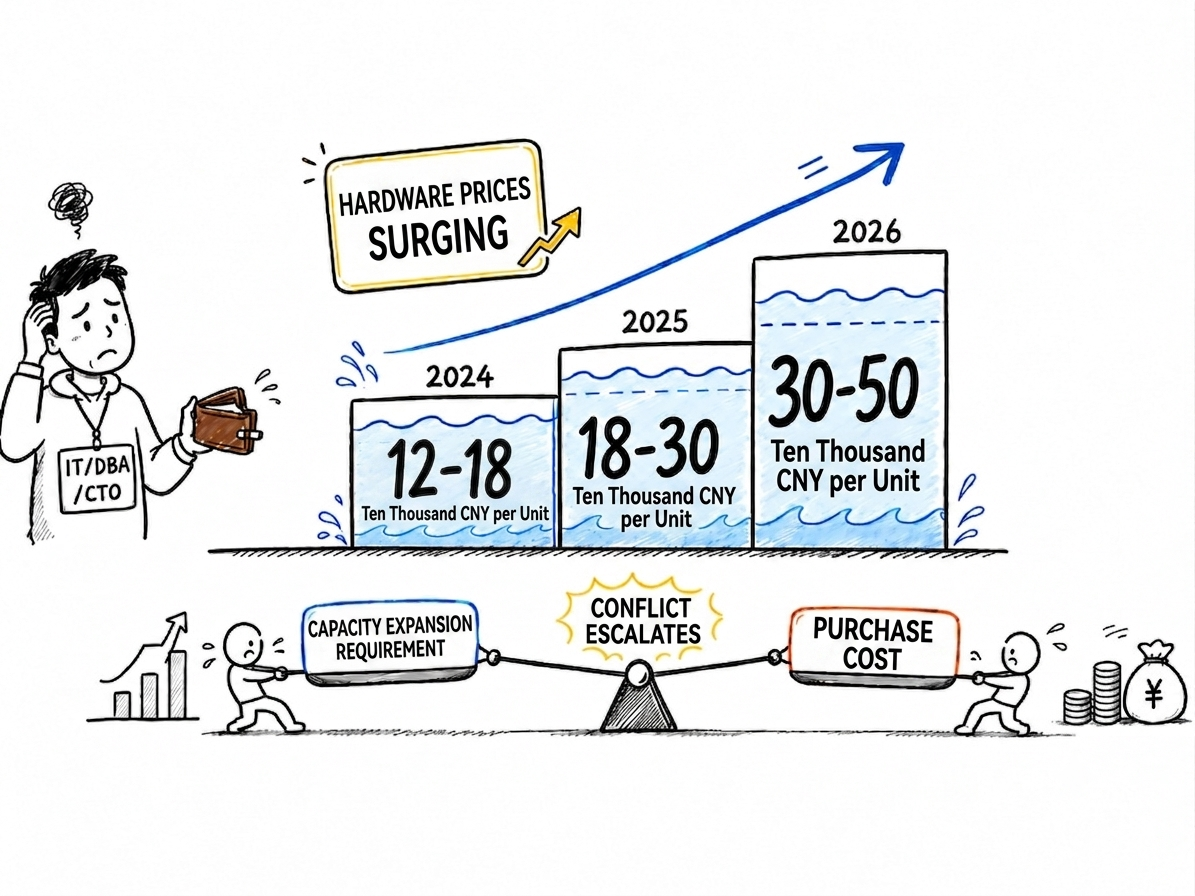
For many enterprises, database cost is no longer just a software expense—it is a comprehensive investment spanning servers, storage, networking, backup, peripheral systems, and operations. This is also where database selection logic is shifting. In the past, customers focused mainly on whether a database could run and deliver sufficient performance. Today, more and more customers also ask whether the same hardware configuration can run more stably, for longer, and with higher efficiency. Database Cost Restructuring in a Financial-Grade System
In a migration project at a leading financial trading institution, we encountered a very typical scenario. The system used a total of 16 database servers, each configured as a high-spec machine for database workloads: 128 CPU cores, 512 GB memory, dual 25GbE networking, enterprise SATA SSDs, and hardware RAID. The overall investment in hardware, maintenance, rack space, and future scaling was substantial.
In the original Greenplum environment, the data volume was approximately 115 TB. After migrating to YMatrix, the same business data occupied only around 80 TB. In other words, data storage alone was reduced by approximately 35 TB, a reduction of around 30% in storage footprint, while data density per unit of hardware increased by approximately 45%. When extrapolated to the customer’s full production scale, the resource efficiency gains would be further amplified. Based on their production expansion model, the potential savings exceeded 100 servers, corresponding to approximately RMB 30 million in hardware and associated costs.
As server prices continue to rise, resource efficiency is no longer just a fine-tuning detail within database internals—it has become a critical factor in whether enterprise data infrastructure can continue to evolve sustainably. This is exactly what YMatrix aims to address. The core value of YMatrix is not simply to reduce the number of servers or eliminate auxiliary components, but to improve resource efficiency at both the database kernel and system architecture levels, enabling enterprises to store more data, handle more complex queries, and support higher throughput on the same hardware—thereby reducing long-term costs caused by premature scaling, redundant construction, and resource waste.
YMatrix Resource Efficiency Solution: Enabling Each Server to Do More In response to continuously rising database costs, YMatrix provides a systematic solution that fundamentally improves the effective workload capacity per server. This can be summarized into five directions:
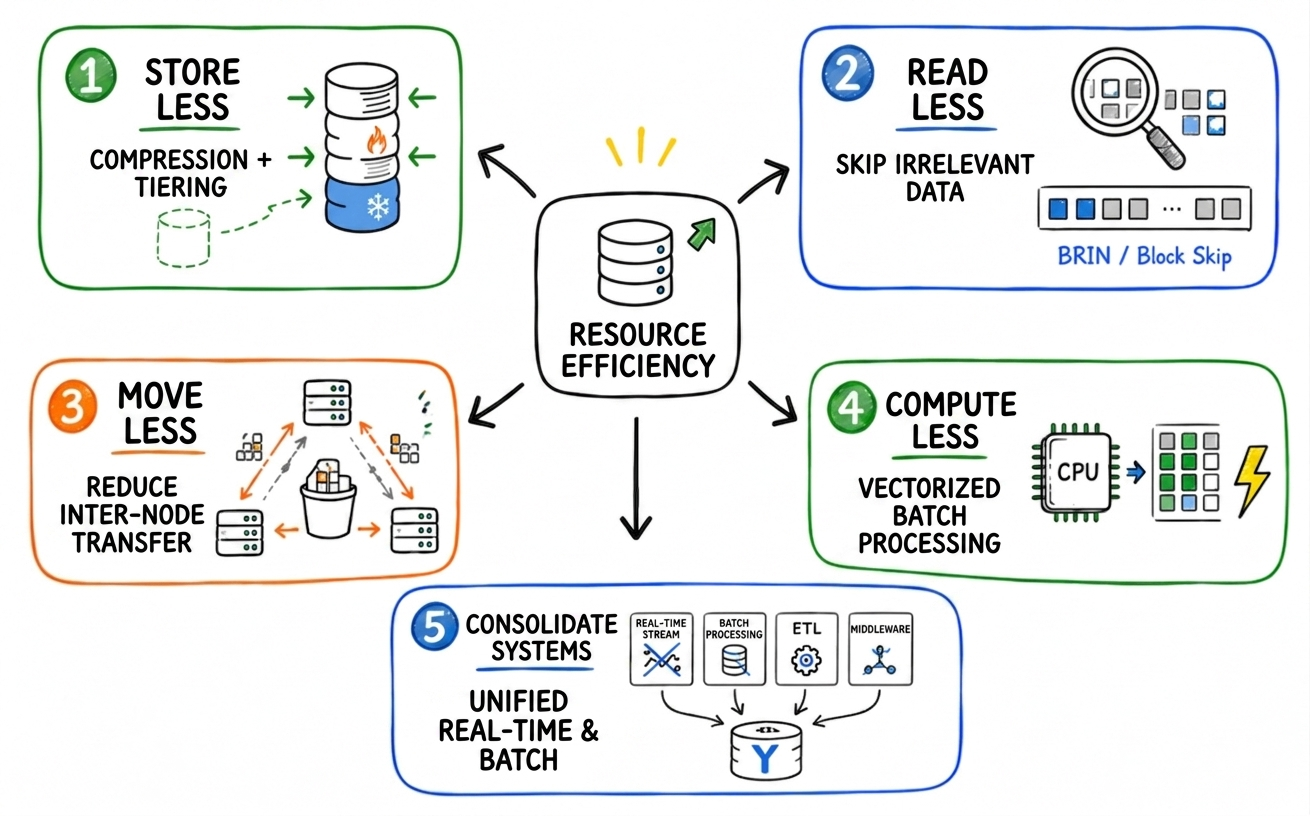
Less Storage
Through self-developed MARS3 storage engine, YMatrix quickly ingests newly written data and reorganizes it in the background into a columnar format that is more suitable for analytics and compression. Combined with column compression, index compression, proprietary encoding chains, and tiered storage, data is stored more compactly while being allocated to appropriate storage tiers based on hot/cold characteristics, reducing unnecessary footprint and high-cost storage waste.
Less Reading
With MARS3 capabilities such as BRIN and block skip, the database can determine which data blocks are likely to match query conditions before scanning, skipping irrelevant blocks entirely. Together with block-level statistics and optimized access paths, only the truly needed data is read.
Less Data Movement
In distributed query scenarios, network transmission is a major cost component. YMatrix reduces data movement through network compression and MARS3 Bucket. Network compression significantly reduce the amount of data transmitted between nodes, while MARS3 Bucket organizes data within each node into buckets so that parallel processes only handle their assigned data. This preserves locality and distribution semantics, significantly reducing unnecessary cross-node data transfer.
Less Computation
While the previous optimizations reduce storage, I/O, and data transfer, computation still needs to be executed. CPU efficiency directly determines how many queries a server can handle. YMatrix uses a vectorized execution engine that processes data in batches rather than row by row. This better leverages CPU cache and modern processor capabilities, reduces repeated overhead, and makes analytical operations such as scanning, filtering, aggregation, sorting, and joins significantly more efficient.
Fewer Systems
Many enterprises also face growing cost pressure from increasingly complex data pipelines outside the database itself. To achieve real-time analytics, traditional architectures often require message queues, stream processing engines, and ETL platforms. Data continuously moves across systems, is repeatedly stored and computed, increasing infrastructure costs and complicating development, operations, troubleshooting, and data consistency management.
Through its Domino in-database stream-batch integration capability, YMatrix enables real-time computation, continuous aggregation, and metric updates directly within the database. Users can define continuous logic using SQL, and when source data changes, downstream results are incrementally updated, allowing real-time analytical outputs to be queried like standard tables. This eliminates the need for external stream processing systems for many workloads, completing the entire data processing loop within the database.
In an era of soaring server costs, the competitive logic of database systems is undergoing a fundamental shift. In the past, when facing data growth or performance degradation, the most common approach was simply to scale hardware. Today, however, the model of endlessly adding machines, storage, networking, and peripheral systems is becoming increasingly expensive and unsustainable.
Against this background, the core capability of a database is no longer just whether it can store data, but whether it can handle more effective workloads with the same resources. Resource efficiency is therefore becoming a more critical evaluation dimension than single-point performance. The cost reduction emphasized by YMatrix is not about cutting a single cost item. Rather, it is about holistic optimization across storage, computation, I/O, networking, and system architecture—enabling data systems to achieve higher density and lower scaling frequency under the same hardware conditions. In this way, databases evolve from “relying on more servers” to “making better use of servers.”
China Telecom Completes SAP HANA Localization Upgrade
Smart Manufacturing at Scale with YMatrix HTAP: Real-Time Ingestion & Unified Analytics
YMatrix HTAP Transforms Month-End Closing for a 16,000-Store Pharma Chain
Dahshenlin: Achieving Real-Time Finance-Operations Integration with a Modernized Data Foundation
SERES × YMatrix: 3-Hour Migration of 2.13TB, 50% Faster Multi-Scenario Queries